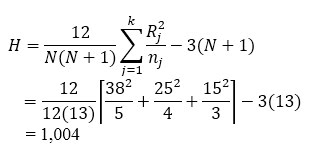NAMA : Marandika Asa
NIM : 21090114130122
Analisis Varian Ranking Satu Arah Kruskal-Wallis
(Uji Kruskal-Wallis)
Analisis varian ranking satu arah Kruskal-Wallis atau
biasa disebut Uji Kruskal-Wallis pertama kali diperkenalkan oleh William H.
Kruskal dan W. Allen Wallis pada tahun 1952. Uji ini merupakan salah satu uji
statistik nonparametrik dalam kasus k sampel independen. Uji Kruskal-Wallis digunakan
untuk menguji apakah k sampel independen berasal dari populasi yang berbeda,
dengan kata lain uji ini dapat digunakan untuk menguji hipotesis nol bahwa k
sampel independen berasal dari populasi yang sama atau identik dalam hal harga
rata-ratanya. Oleh karena itu, uji Kruskal-Wallis juga merupakan perluasan dari
uji Mann-Whitney.
Menurut D.C. Montgomery (2005), apabila asumsi
kenormalan yang dibutuhkan oleh metode statistika parametrik tidak dapat
dipenuhi, maka peneliti dapat menggunakan metode alternatif sebagai pengganti
analisis varian satu arah (One way ANOVA) yaitu Kruskal-Wallis Test. Sedangkan
menurut Wayne W. Daniel dalam bukunya Applied
Nonparametric Statistic, beberapa syarat yang harus dipenuhi dalam
menggunakan Kruskal-Wallis Test adalah:
1.
Pengamatan harus bebas satu
sama lain (tidak berpasangan/independent).
2.
Tipe data setidak-tidaknya
adalah ordinal.
3.
Variabel yang diamati merupakan
variabel yang berdistribusi kontinyu.
Dasar
Pemikiran dan Metode
Data untuk pengujian Kruskal-Wallis pada umumnya
dituangkan dalam tabel N baris dan k kolom. Banyaknya sampel yang terpilih
dituliskan dalam tabel secara baris, sedangkan kelompok atau kategori yang
tersedia dituliskan secara kolom.
Dalam penghitungan uji Kruskal-Wallis ini, masing-masing
nilai observasi diberi ranking secara keseluruhan dalam satu rangkaian.
Pemberian ranking diurutkan dari nilai yang terkecil hingga nilai yang
terbesar. Nilai yang terkecil diberi ranking 1 dan nilai yang terbesar diberi
ranking N (dimana N adalah jumlah seluruh observasi). Apabila terdapat angka
yang sama, maka ranking dari nilai-nilai tersebut adalah rata-rata ranking dari
nilai-nilai observasi tersebut.
Jika seluruh nilai observasi telah diberi ranking,
langkah selanjutnya adalah menghitung jumlah ranking dari masing-masing kolom (Rj).
|
Sampel
|
Kelompok /
Kategori
|
|
1
|
R
|
2
|
R
|
…
|
k
|
R
|
|
1
2
.
.
.
nj
|
X11
X21
Xn1
|
R11
R21
Rn1
|
X12
X22
Xn2
|
R12
R22
Rn2
|
…
…
…
|
X1k
X2k
Xnk
|
R1k
R2k
Rnk
|
|
Rj
|
-
|
R1
|
-
|
R2
|
…
|
-
|
Rk
|
Selanjutnya, uji
Kruskal-Wallis dapat didefinisikan dengan rumus:
H: nilai Kruskal-Wallis dari
hasil penghitungan
Rj: jumlah rank
dari kelompok/kategori ke-j
nj : banyaknya kasus
dalam sampel pada kelompok/kategori ke-j
k: banyaknya kelompok/kategori
N: jumlah seluruh observasi
(N=n1+n2+n3+………..+nk)
|
|
dimana,
H: nilai Kruskal-Wallis dari hasil
penghitungan
Rj: jumlah rank dari kelompok/kategori
ke-j
nj : banyaknya kasus dalam sampel pada
kelompok/kategori ke-j
k: banyaknya kelompok/kategori
N: jumlah seluruh observasi (N=n1+n2+n3+………..+nk)
Jika ditemukan angka sama sebanyak lebih dari 25% nilai
observasi sehingga mengakibatkan banyak
nilai ranking yang sama, maka perlu adanya koreksi pada rumus
penghitungan uji Kruskal-Wallis, dengan faktor koreksinya adalah:
dimana,
t : banyaknya nilai observasi
tertentu yang sama pada serangkaian nilai observasi
N
: jumlah seluruh observasi (N=n1+n2+n3+………..+nk)
Sehingga rumus uji Kruskal-Wallis dengan kasus angka sama berjumlah
banyak adalah:
Metode dan Prosedur
1.
Penentuan Hipotesis Nol dan Hipotesis
Alternatif
H0 : k sampel berasal dari populasi yang sama
H1 : k sampel berasal dari populasi yang berbeda
2.
Menentukan Tes Statistik /
Statistik Uji
Karena tujuannya adalah menguji apakah k sampel independen berasal
dari populasi yang sama maka uji statistik yang kita gunakan adalah uji
Kruskal-Wallis dengan statistik ujinya H yang berdistribusi Chi-Square dengan
derajat bebas (k-1).
3.
Menentukan Tingkat Signifikansi
Tingkat signifikansi a adalah
bilangan yang mencerminkan besarnya peluang menolak hipotesis nol ketika
hipotesis nol bernilai benar.
4.
Distribusi Sampling
H mendekati distribusi Chi-Square dengan derajat bebas
(k-1). Nilai H dapat dihitung dengan Rumus (8.1). Adapun ketentuan penggunaan tabel adalah sebagai berikut:
a.
Jika k=3 dan nj £ 5 (j=1;2;3), Tabel O dapat digunakan untuk menentukan nilai yang
berkaitan dengan harga di bawah H0.
b.
Dalam kasus lain, dapat
digunakan Tabel C dengan derajat bebas (k-1)
5.
Daerah Penolakan
Daerah penolakan terdiri dari semua harga H yang sedemikian besar sehingga
kemungkinan yang berkaitan dengan terjadinya harga – harga itu di bawah H0
sama dengan atau kurang dari a.
6.
Keputusan
H0 akan ditolak jika nilai H ³ ca(k-1) atau nilai p-value £ a sebaliknya H0 akan gagal
ditolak jika nilai H < ca(k-1) atau nilai p-value > a.
Ringkasan Prosedur
1.
Berilah ranking pada masing –
masing nilai observasi dengan urutan dari ranking 1 hingga N.
2.
Tentukan harga R (jumlah
ranking) untuk masing – masing kelompok atau kategori.
3.
Jika ditemukan angka sama
sebanyak lebih dari 25% nilai observasi, maka hitunglah harga H dengan
menggunakan Rumus (8.3). Jika tidak, gunakanlah Rumus (8.1).
4.
Metode untuk menilai
signifikansi harga observasi H bergantung pada besarnya k dan banyaknya sampel
pada setiap kelompok/kategori tersebut.
a.
Jika k=3 dan nj £ 5 (j=1;2;3), Tabel O dapat digunakan untuk menentukan nilai yang
berkaitan dengan harga di bawah H0.
b.
Dalam kasus lain, dapat
digunakan Tabel C dengan derajat bebas (k-1).
5.
Jika kemungkinan yang berkaitan
dengan harga observasi H adalah sama atau kurang dari a, maka tolak H0 dan terima H1.
Contoh Soal Uji Kruskal-Wallis
Contoh 1
Untuk membandingkan tingkat keefektifan dari 3 macam metode
diet, maka sebanyak 22 orang mahasiswi yang dipilih dari suatu universitas dibagi
ke dalam 3 kelompok yang mana masing-masing kelompok mengikuti program diet
selama empat minggu sesuai dengan metode yang telah dibuat. Setelah program
diet berakhir, maka diperoleh banyaknya berat badan yang hilang (dalam kg) dari
mahasiswi-mahasiswi tersebut sebagai berikut:
|
Metode Diet 1
|
Metode Diet 2
|
Metode
Diet 3
|
|
Sampel
|
Berat Badan (BB) yg hilang
|
Sampel
|
Berat Badan (BB) yg hilang
|
Sampel
|
Berat Badan (BB) yg hilang
|
|
1
|
5,3
|
1
|
6,3
|
1
|
2,4
|
|
2
|
4,2
|
2
|
8,4
|
2
|
3,1
|
|
3
|
3,7
|
3
|
9,3
|
3
|
3,7
|
|
4
|
7,2
|
4
|
6,5
|
4
|
4,1
|
|
5
|
6,0
|
5
|
7,7
|
5
|
2,5
|
|
6
|
4,8
|
6
|
8,2
|
6
|
1,7
|
|
|
|
7
|
9,5
|
7
|
5,3
|
|
|
|
|
|
8
|
4,5
|
|
|
|
|
|
9
|
1,3
|
Untuk menguji Ho
yang menyatakan bahwa tingkat keefektifan dari ketiga metode diet di atas adalah
sama, terhadap hipotesis alternatif yang menyatakan bahwa tingkat keefektifan ketiga
metode di atas adalah tidak sama (α = 5%).
Jawaban :
o
Hipotesis
H0 : tingkat
keefektifan dari ketiga metode diet adalah sama
H1 : tingkat
keefektifan dari ketiga metode diet adalah tidak sama
o
Tes Statistik : Kruskal-Wallis Test
o
Tingkat Signifikansi : α=5%,
o
Distribusi sampling :
H mendekati
distribusi Chi-Square dengan derajat bebas (k-1), sehingga wilayah kritis dapat
ditentukan dengan menggunakan Tabel C.
o
Penghitungan
n1=6 ; n2=7
; n3=9 ; N= n1 + n2
+ n3 = 22
|
Metode
Diet 1
|
Metode
Diet 2
|
Metode
Diet 3
|
|
BB
yg hilang
|
Ranking
|
BB yg hilang
|
Ranking
|
BB yg hilang
|
Ranking
|
|
5,3
|
12,5
|
6,3
|
15
|
2,4
|
3
|
|
4,2
|
9
|
8,4
|
20
|
3,1
|
5
|
|
3,7
|
6,5
|
9,3
|
21
|
3,7
|
6,5
|
|
7,2
|
17
|
6,5
|
16
|
4,1
|
8
|
|
6,0
|
14
|
7,7
|
18
|
2,5
|
4
|
|
4,8
|
11
|
8,2
|
19
|
1,7
|
2
|
|
|
|
9,5
|
22
|
5,3
|
12,5
|
|
|
|
|
|
4,5
|
10
|
|
|
|
|
|
1,3
|
1
|
|
|
R1 = 70
|
|
R2 = 131
|
|
R3 = 52
|
= 15,633
o
Daerah penolakan : H ³ ca(k-1) atau p-value £ a
o
Keputusan :
c0,05(2) = 5,991
 Karena
15,633 > 5,991 H > c0,05(2) , maka Tolak H0
Karena
15,633 > 5,991 H > c0,05(2) , maka Tolak H0
o
Kesimpulan : Dengan tingkat kepercayaan 95 %, belum cukup bukti untuk menyatakan bahwa tingkat keefektifan dari ketiga metode
diet tersebut adalah sama.
Contoh 2
Manajemen restoran fastfood sangat ingin tahu pendapat langganannya
mengenai pelayanan, kebersihan dan kualitas makanan dari restorannya.
Pihak management ingin membandingkan hasil rating pelanggan untuk tiga shift yang
berbeda, yaitu:
Shift 1: 16.00 – midnight
; Shift 2: midnight – 08.00 ; Shift 3: 08.00 – 16.00
Pelanggan diberi kesempatan untuk
mengisi kartu saran. Pada penelitian ini 10 kartu saran (customer card) dipilih secara random, untuk
setiap shift. Rating digolongkan dalam empat kategori
yaitu 4 = sempurna, 3 = baik, 2 = biasa, 1 = buruk. Diperoleh data seperti
dibawah ini:
|
16.00 - Midnight
|
Midnight - 08.00
|
08.00 - 16.00
|
|
4
|
3
|
3
|
|
4
|
4
|
1
|
|
3
|
2
|
3
|
|
4
|
2
|
2
|
|
3
|
3
|
1
|
|
3
|
4
|
3
|
|
3
|
3
|
4
|
|
3
|
3
|
2
|
|
2
|
2
|
4
|
|
3
|
3
|
1
|
Dengan tingkat kepercayaan 95%, dapatkah
pihak manajemen mengatakan bahwa karyawannya memberikan pelayanan, kebersihan,
dan kualitas makanan yang sama sepanjang hari?
Jawaban :
o
Hipotesis
H0 : Tidak ada
perbedaan rating pelanggan untuk
pelayanan, kebersihan, dan kualitas makanan antara ketiga shift tersebut.
H1 : Ada
perbedaan rating pelanggan untuk
pelayanan pelayanan, kebersihan, dan kualitas makanan antara ketiga shift
tersebut.
o
Tes Statistik : Kruskal-Wallis Test.
Persoalan di atas merupakan persoalan k sampel independent. Karena data berada
pada skala pengukuran ordinal (ranking), maka Kruskal-Wallis Test dapat
digunakan.
o
Tingkat Signifikansi : α = 0,05
o
Distribusi sampling :
H mendekati
distribusi Chi-Square dengan derajat bebas (k-1), sehingga wilayah kritis dapat
ditentukan dengan menggunakan Tabel C.
o
Penghitungan
n1= n2=
n3=10 ; N= n1 + n2
+ n3 = 30
|
16.00-Midnight
|
Rank
|
Midnight-08.00
|
Rank
|
08.00-16.00
|
Rank
|
|
4
|
27
|
3
|
16.5
|
3
|
16.5
|
|
4
|
27
|
4
|
27
|
1
|
2
|
|
3
|
16.5
|
2
|
6.5
|
3
|
16.5
|
|
4
|
27
|
2
|
6.5
|
2
|
6.5
|
|
3
|
16.5
|
3
|
16.5
|
1
|
2
|
|
3
|
16.5
|
4
|
27
|
3
|
16.5
|
|
3
|
16.5
|
3
|
16.5
|
4
|
27
|
|
3
|
16.5
|
3
|
16.5
|
2
|
6.5
|
|
2
|
6.5
|
2
|
6.5
|
4
|
27
|
|
3
|
16.5
|
3
|
16.5
|
1
|
2
|
|
|
R1
= 186.5
|
|
R2
= 156
|
|
R3
= 122.5
|
Penghitungan
untuk angka sama dengan koreksi:
|
Nilai
Observasi
|
1
|
2
|
3
|
4
|
|
t
|
3
|
6
|
14
|
7
|
|
T
|
24
|
210
|
2730
|
336
|
= 3,01
o
Daerah penolakan : H ³ ca(k-1) atau p-value £ a
o
Keputusan :
c0,05(2) = 5,991
 Karena
3,01 < 5,991 H < c0,05(2) , maka gagal tolak H0
Karena
3,01 < 5,991 H < c0,05(2) , maka gagal tolak H0
o
Kesimpulan : Dengan tingkat kepercayaan
95 %, belum cukup bukti untuk menyatakan bahwa ada perbedaan rating pelanggan untuk pelayanan,
kebersihan, dan kualitas makanan antara ketiga shift tersebut.
Contoh 3
Sebuah perusahaan ingin mengetahui apakah terdapat
perbedaan keterlambatan masuk kerja antara pekerja yang rumahnya jauh atau
dekat dari lokasi perusahaan. Misalkan jarak rumah dikategorikan dekat ( kurang
dari 10 km), sedang (10 – 15 km) dan jauh ( lebih dari 15 km). Keterlambatan
masuk kerja dihitung dalam menit keterlambatan selama sebulan terakhir.
Penelitian dilakukan pada tiga kelompok pekerja
dengan sampel acak, dengan masing-masing sampel untuk yang memiliki jarak rumah
dekat sebanyak 5 sampel, jarak sedang sebanyak 4 sampel dan jauh sebanyak 3
sampel. Ujilah dengan tingkat kepercayaan 95 %. Datanya sebagai berikut :
|
Dekat
|
Sedang
|
Jauh
|
|
59
|
77
|
89
|
|
110
|
99
|
102
|
|
132
|
128
|
121
|
|
143
|
144
|
|
|
165
|
|
|
Jawaban :
o
Hipotesis
H0 : Tidak ada
perbedaan lama keterlambatan antara tiga kategori pekerja berdasarkan jarak
rumahnya.
H1 : Ada
perbedaan lama keterlambatan antara tiga kategori pekerja berdasarkan jarak
rumahnya
o
Tes Statistik : Kruskal-Wallis Test.
Karena data berada pada skala pengukuran rasio (lama keterlambatan), maka
kruskal-wallis dapat digunakan.
o
Tingkat Signifikansi : α = 0,05
o
Penghitungan
n1= 5 ; n2=
4 ; n3= 3 ; N= n1 + n2 + n3 = 12
|
Dekat
|
Rank
|
Sedang
|
Rank
|
Jauh
|
Rank
|
|
59
|
1
|
77
|
2
|
89
|
3
|
|
110
|
6
|
99
|
4
|
102
|
5
|
|
132
|
9
|
128
|
8
|
121
|
7
|
|
143
|
10
|
144
|
11
|
|
|
|
165
|
12
|
|
|
|
|
|
|
R1 = 38
|
|
R2
= 25
|
|
R3
= 15
|
= 1,004
o
Daerah penolakan : p-value £ a
o
Keputusan :
Karena k=3 dan nj £ 5 (j=1;2;3), maka kita dapat menggunkan Tabel O untuk menentukan
nilai yang berkaitan dengan harga di bawah H0.
Dari tabel O untuk nilai  ,
,  , dan
, dan  , p-value
untuk H = 1,004 adalah lebih besar dari 0,103 (p-value > 0,103). Karena p-value > 0,05 , maka gagal tolak H0
, p-value
untuk H = 1,004 adalah lebih besar dari 0,103 (p-value > 0,103). Karena p-value > 0,05 , maka gagal tolak H0
o
Kesimpulan : Dengan tingkat kepercayaan
95 %, belum cukup bukti untuk menyatakan bahwa ada perbedaan lama keterlambatan
antara tiga kategori pekerja berdasarkan jarak rumahnya.